Machine Learning (ML) 中文是機器學習,顧名思義是讓機器透過過往的資料去學習“規則”,以應用於預測未來或產生解答。
相似的名詞(大家很常搞混的)還有 Deep Learning, Data Mining, Data Science, Big Data…
以下就針對這幾個詞稍微介紹他們的不同之處。
- Deep Learing 深度學習
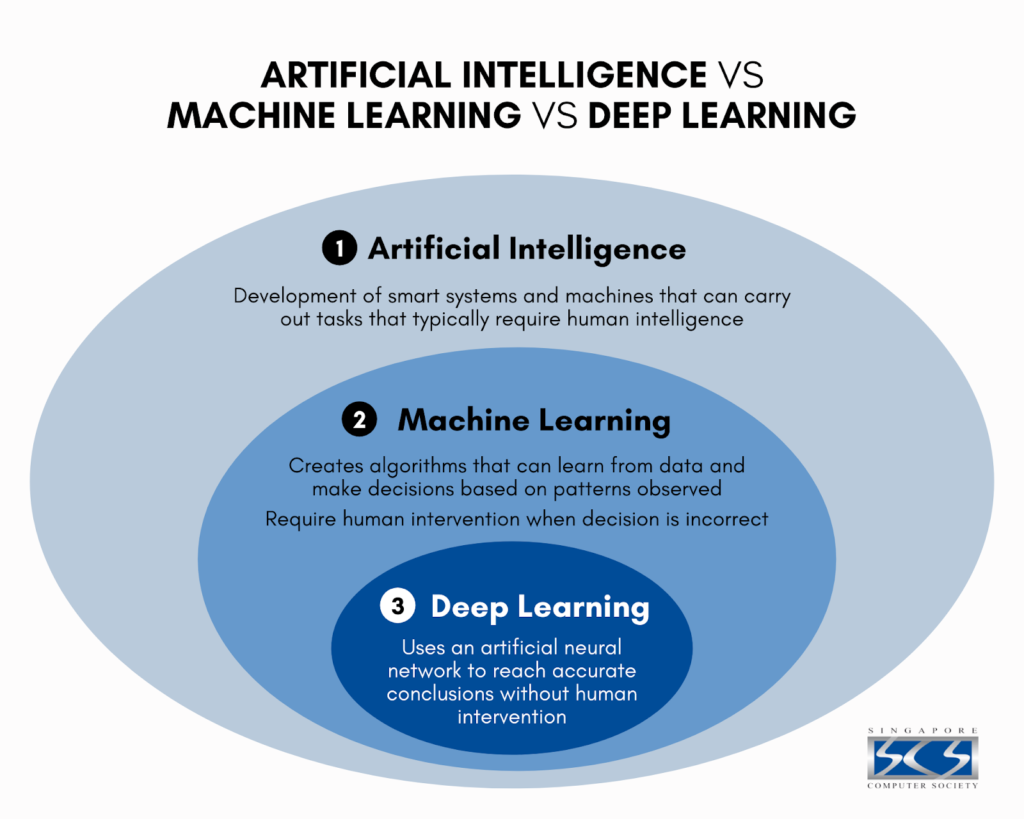
- 是隸屬於ML的範疇內,差別在於DL擅長解決圖像的分析,且多是透過“黑盒子”(即不可以解釋性)產生非常準確的答案。
- Data Mining 資料探勘
- 從資料找出 有效的valid\意外的suprising\可用的workable\可解釋性interrpritation Pattern
- 又稱Pattern mining
- Data Science 資料科學
- Data Mining + Visualization + Interpretation for Decision Support
- 重點在輔助人類做決策Decision Support
- Story Telling 能力,從資料中解讀,並且說故事,也要能夠視覺化展示資料
- Data Sciencist 就是在解讀資料
- Big Data 大數據
- Data Mining + Cloud Computing(重點)
- 重點是結合雲端運算,可以平行運算
以上介紹完各種名詞,大家應該比較有感覺了吧!
Machine Learning要做什麼?
ML 用於解決特定的問題 How can we solve a specific problem?
As computer scientists we write a program that encodes a set of rules that are useful to solve the problem.
In many cases is very difficult to specify those rules.
e.g., given a picture determine whether there is a dog in the image?
學習系統不是直接靠programing來解決問題,而是根據以下內容開發自己的程序:
- Examples of how they should behave
- From trial-and-error experience trying to solve the problem
ML中所謂的學習(或你可以稱為知識)只是將從訓練資料中得到的資訊整合到系統當中。
很重要的一點是,在機器學習的概念裡,我們是假設“歷史會重演“進而去做訓練以及預測。所以對於沒有發生過的案例,機器學習也只能從過往中找中一個最相近的例子當做參考。

什麼樣的問題適合用ML去解決?
ML的範疇非常廣,甚至Deep Learning(DL) 也是 ML的一部分。
ML結構: 資料→特徵擷取→模型→答案
DL結構: 資料→模型(特徵擷取自學)→答案
舉凡目前的模型任務主要有以下幾種:
- 分類 Classification
- 回歸 Regression
- 分群 Cluster
只要你有資料且要做上述的任務,就可以用ML的結構去建構模型。
在現今,非常多的開源模型架構可以直接套用,資源都非常好取得,建構模型以及機器學習也不再是一個遙遠的名詞。